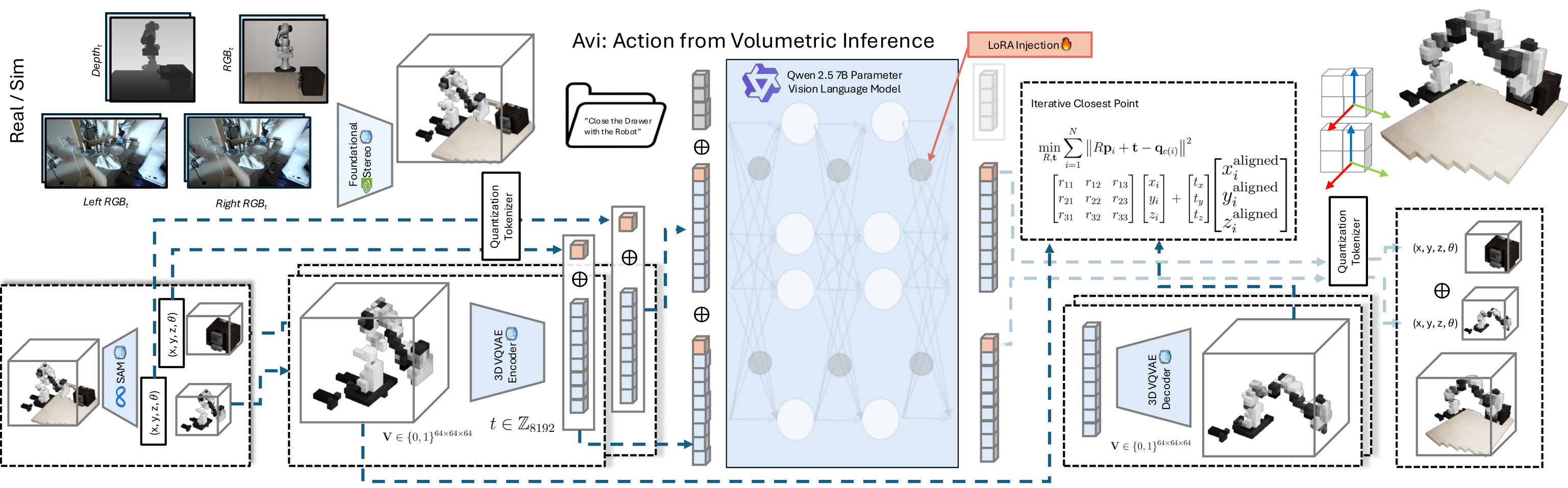
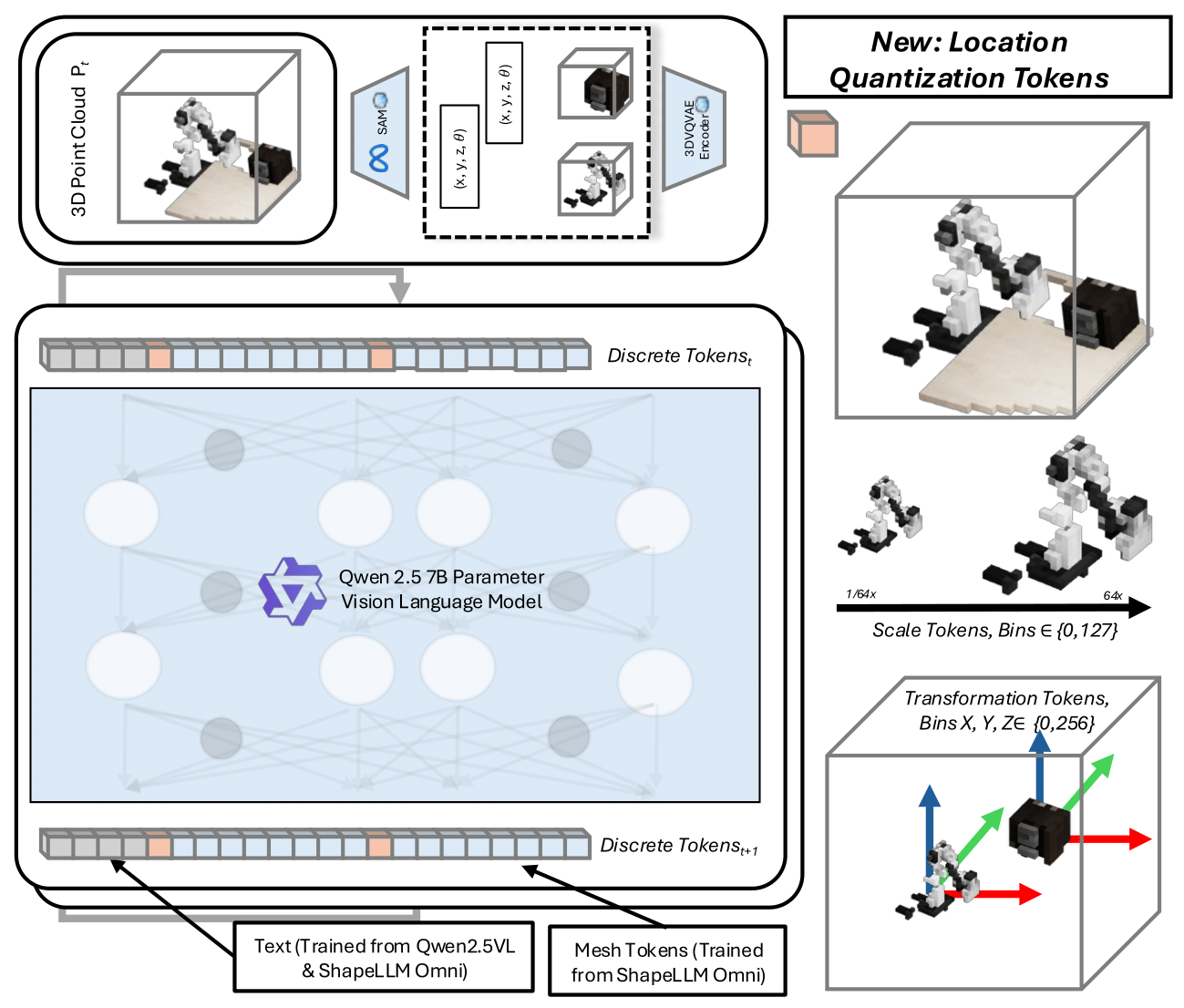
Architecture Overview
Our architecture extends the foundational 3D model, ShapeLLM-Omni, which is pretrained on
large-scale 3D assets and capable of handling multi-modal inputs, including text, images,
and 3D point clouds. We integrate Qwen-2.5 (7B), a state-of-the-art large vision-language
model, with ShapeLLM-Omni to inherit both powerful linguistic grounding and native 3D spatial
reasoning.
Location Quantization
We extend the vocabulary by introducing dedicated position and scale tokens. Specifically,
we define three independent position axes: X, Y, Z ∈ {1,2,...,256}, each discretized into
256 bins, and discretize object scale into S ∈ {1,2,...,128}, yielding 128 scale tokens.
This introduces a total of 896 additional tokens for spatial context.
Transformation Calculation
Given a prompt and current scene point cloud Pt, we generate a next point cloud
prediction P̂t+1 such that: P̂t+1 ≈ Pt + ΔP where ΔP
represents the learned spatial change conditioned on the prompt. We then compute the
Iterative Closest Point (ICP) transformation to minimize alignment error.
The system processes both geometric and linguistic inputs by mapping them into a shared
latent space Z. Let P denote the input point cloud and T the human-provided text prompt.
We define modality-specific encoders such that: f3D(P) ∈ Z, ftext(T) ∈ Z,
where f3D and ftext are encoders for the 3D point cloud and text, respectively.
This joint embedding ensures that both geometry and language are represented in a unified
feature space, enabling cross-modal reasoning.
For the language backbone, we integrate Qwen-2.5 (7B), a state-of-the-art large vision-language
model with 7 billion parameters. Qwen-2.5 provides strong multi-turn instruction-following,
chain-of-thought reasoning, and multilingual capabilities, making it particularly well-suited
for language-conditioned robotics.